Developer Guide
This guide is tailored to developers who wish to contribute to the project. It focuses on all the features from a low-level perspective while keeping it fairly simple. Instead of describing all the little functions it mainly focuses on features and what parts of the system are involved when working on the given feature.
Build Pipelines
Here is a diagram to provide a nicer graphical representation of the entire pipeline.
|
Find additional content below the schema. |
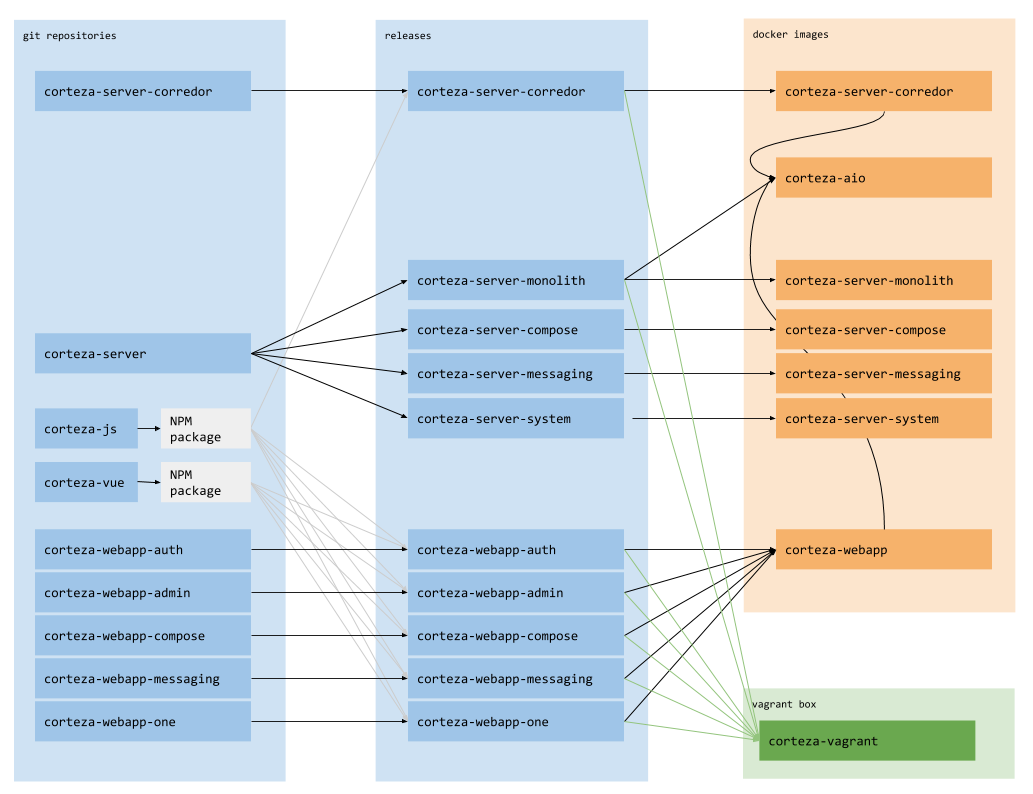
Node packages
corteza-js and corteza-vue are bundled using Rollup and released to the npm repository.
Releasing
All of the main Corteza applications are tested and build using Drone CI. The resulted binaries, bundles - in case of webapp projects - and other assets are placed on https://release.cortezaproject.org.
Packaging
At the moment we officially only support packing into Docker images. Built docker images are then pushed to the DockerHub.
Unofficially, you can use the released packages with a Vagrant box https://github.com/cortezaproject/corteza-vagrant.
Alternatively you can (build and) install these packages manually, either on the virtual machine or a regular machine.
|
Actual releases are done by the core team. |
Release cycle
Pre-release checklist
|
The pre-release checklist is a reference for the core Corteza team to help us keep a consistent flow when preparing for a release. If you are curious, keep on reading; else, you can skip this. |
Update any dependency warning
Go over each repository and assure that there aren’t any warnings with any of the dependencies. GitHub provides a friendly system for this, so that shouldn’t be an issue.
-
corteza-js: (https://github.com/cortezaproject/corteza-js)
-
corteza-vue: (https://github.com/cortezaproject/corteza-vue)
-
corteza-server-corredor: (https://github.com/cortezaproject/corteza-server-corredor)
-
corteza-webapp-auth: (https://github.com/cortezaproject/corteza-webapp-auth)
-
corteza-webapp-one: (https://github.com/cortezaproject/corteza-webapp-one)
-
corteza-webapp-admin: (https://github.com/cortezaproject/corteza-webapp-admin)
-
corteza-webapp-messaging: (https://github.com/cortezaproject/corteza-webapp-messaging)
-
corteza-webapp-compose: (https://github.com/cortezaproject/corteza-webapp-compose)
Bump version, build and publish packages
Bump the version of the NPM packages, following the CalVer standard; for example 2020.9-rc1.
Build and publish new packages.
-
corteza-js: (https://github.com/cortezaproject/corteza-js)
-
corteza-vue: (https://github.com/cortezaproject/corteza-vue)
Update cdeps (Corteza Dependencies)
Go over all repositories that use these and make sure they are up to date.
You can use the yarn cdeps command to speed it up.
-
corteza-server-corredor: (https://github.com/cortezaproject/corteza-server-corredor)
-
corteza-webapp-auth: (https://github.com/cortezaproject/corteza-webapp-auth)
-
corteza-webapp-one: (https://github.com/cortezaproject/corteza-webapp-one)
-
corteza-webapp-admin: (https://github.com/cortezaproject/corteza-webapp-admin)
-
corteza-webapp-messaging: (https://github.com/cortezaproject/corteza-webapp-messaging)
-
corteza-webapp-compose: (https://github.com/cortezaproject/corteza-webapp-compose)
Bump core repo version
Go over all of the remaining repositories and update their version, following the CalVer standard; for example 2020.9-rc1.
-
corteza-server: (https://github.com/cortezaproject/corteza-server)
-
corteza-server-corredor: (https://github.com/cortezaproject/corteza-server-corredor)
-
corteza-webapp-auth: (https://github.com/cortezaproject/corteza-webapp-auth)
-
corteza-webapp-one: (https://github.com/cortezaproject/corteza-webapp-one)
-
corteza-webapp-admin: (https://github.com/cortezaproject/corteza-webapp-admin)
-
corteza-webapp-messaging: (https://github.com/cortezaproject/corteza-webapp-messaging)
-
corteza-webapp-compose: (https://github.com/cortezaproject/corteza-webapp-compose)
Documentation
Contribution Rules
Below is a list of rules that apply to every contributor of any Corteza repository. With the below points we are able to provide consistent, quality software that is easy to use or contribute to.
- All major modifications must be documented
-
A modification classifies as major when it causes any changes to an actions output or how the action is performed. For example:
-
Changed api response,
-
change in the access control logic,
-
additional settings, environment variables,
-
changed the interface for data export,
-
new features; etc.
-
- All relevant guides must me updated
-
When a modification affects multiple guides, each of them needs to be taken care of. For example, your feature introduces a new application with a special API and a user interface. You should update:
-
Developer guide,
-
administrator guide,
-
end-user guide.
-
- Consistent style of writing
-
Be consistent with other contributors as we wish to have a consistent, easy to read documentation. Refer to Writing Guidelines for more insight on this.
- Try to follow the rules
-
In the edge case where it is excusable for you to not follow the above rules (extremely tight schedule, urgent fixes that need to be released asap, …) open up an issue that outlines your changes, provides some references to the PR/commit so someone (preferably yourself) can get to it as soon as possible. No big deal, as long as it gets done before the release.
|
If you refuse to follow the above guidelines for any reason, you will not be able to contribute to the project. We all hate it when an amazing framework or platform lacks in documentation and we have to reverse engineer every little feature. How good is a product if no one knows how to use or maintain it? Let’s not make our lives harder by not wanting to share our knowledge! |
|
Stuck? Get in touch with us on https://latest.cortezaproject.org! |
Conventions
You can use all of the formatting and different components that AsciiDoc allows. We do define some exceptions for better consistency when working with more flexible components. The conventions listed below must be followed when contributing to any part of the documentation.
Lists
- Ordered lists
-
Ordered lists should be defined with the
.instead of using actual numbers. For example:
. List point 1,
. list point 2.- Unordered lists
-
Unordered lists should be defined with the
*. For example:
* List point 1,
* list point 2.|
Use ordered/unordered lists only when the lines are relatively short. If the list should provide detailed description, use the multi-line description block: For example: |
Code snippets
- Short one-liners
-
When specifying short code snippets such as a CLI command use the single backtick (
`), - Longer code snippets
-
Try to avoid long code snippets as much as possible unless when working on examples. Use the source code syntax
[source,{language here}]blocked 4 dashes----. For example:
[source,adoc]
----
----Writing Guidelines
We outline the most important writing style rules that must be followed when you contribute to Corteza documentation.
|
For more insight refer to this great article https://docs.openstack.org/doc-contrib-guide/writing-style/general-writing-guidelines.html. |
Use active voice
Active voice identifies the subject that has performed the given action; for example:
To configure external login providers go into the administration panel, authentication and configure …
This style makes the reader more involved and therefore makes it nicer and easier to read. It also makes it a bit shorter which is always a plus!
There are some exceptions when active voice should not be used:
-
When we are talking about errors it would sound like we are blaming the user!
-
it makes the sentence much longer.
Use the present simple tense
Users refer to the documentation to find out how something could be done. Lets give them the feeling like we are walking them through this process. This also makes it shorter and a bit easier to read then when other tenses are used.
|
When describing things like asynchronous data processing where it would not make sense to use use present simple tense, use the appropriate tense. |
Use second person
This makes it sound more engaging as it involves more people then just you and I. For example: "I have defined this feature that can be used to …" sounds way better as "We have defined this feature that you can use to …". The use of second person also removes gender-specific things.
Follow the KISS principle!
How many times have we given up on reading documentation because it was all just filler text to produce more and more pages? Lets get straight to the point and tell our readers exactly what they want to know without waisting their time.
Keep things structured
When reading, people usually skim through the content or stop all together when we think we’ve found what we are looking for. If we don’t do any separation between different parts it all becomes one big blob of text. If we split things too much our readers might miss an important bit.
Use admonition
When we want our reader to pay extra attention to something or when we want to provide some helpful tips, don’t hesitate to use admonition blocks. The reader is more likely to pay extra attention to something important if it is contained in a nice red box with the word "Important" next to it.
Use images… sparingly
Don’t go over the top with images by showing every single step of they way or even worse by just pasting a screenshot with no context what we are looking at. When including images make sure to indicate exactly what the image represents and make sure to provide an image caption that outlines what is going on in the image. This allows the reader to easily refresh their memory if they are already familiar with something but just want to refresh their memory.
|
Keep in mind that UI changes will require this images to be updated. |
User Roles
End-User
An end-user is someone who is tasked to perform some operations on the Corteza product or any of the integrations. In most cases, this users are not field experts so we should keep that in mind.
Administrator
An administrator is someone who is responsible to setup and maintain a Corteza instance. This involves everything from the actual deployment, maintenance and permission configuration. These users should be knowledgeable in this fields in order to perform the tasks in an effective manner.
Structure Overview
A few notes before we get into the fun bits:
- There is no "cookie cutter" solution
-
When it comes to such systems, there are multiple different types of users involved. From the end-users who usually aren’t techy people, to administrators that worry about the system’s integrity, to developers that maintain existing features and implement new features. That is why there can’t be a "one fits all" kind of solutions.
- Tell me everything!!
-
Let’s not make our readers jump from one doc to another just because it’s easier that way or it shortens the thing. As a reader of the "Integrator Guide" I want to have all the relevant information without the need reading up on another one.
- Copy paste is ok (sometimes)
-
If different roles are interested in the same thing, for example module field types, let’s not make them jump to another documentation just to read up on that and get lost in the process. Let’s just have it in both places. If we are smart about it, we can define smaller snippets that can be included into both parts.
Overview
Provide a high-level overview over the entire product. Explain to the reader "what exactly this is", what can be achieved and provide some examples what has already been done. We need to get our reader intrigued in this! Cover:
- Product Overview
-
Describe what the product is and what it’s not. Provide some example applications and possible solutions.
- Security
-
Provide a rough overview over the security system - users, roles, access control and so on. Don’t go that much into the details but give the reader a realistic overview over the security system and it’s capabilities.
- Architecture
-
Outline all of the important components and what they are and/or could be used for. Use all the fancy buzz words!
- Development and Contribution
-
Provide a quick outline on how to contribute, define all the available repositories and provide some links to resources. Provide some rules for issue tracking, documentation contributions, …
- Deployment
-
Provide a quick step by step guide on how to setup a fresh Corteza instance.
- Benchmarks
-
Provide some benchmarks, and of course some fancy charts to show the products capabilities.
- Road Map
-
Provide a road map for the near future.
|
Remember! This is meant for non-techy people, so keep it plain and simple. You can use some marketing buzzwords but that’s pretty much it. |
End-User Guide
Provide a high-level overview over all features from the end-user’s perspective. It should be as short and condensed as possible, as the end user doesn’t really care of all the technical details such as what protocols are used, what frameworks are used. All they wish to know is "How do I achieve this while using Corteza". For consistency we define the following structure:
= {APPLICATION_NAME}
// Provide a quick TL;DR of the application.
// What is it's purpose, who can use it, ...
== {APPLICATION_FEATURE_NAME}
// Describe the feature as abstractly as possible while giving the end-user the confidence to use this feature.Important things we need to address:
- APPLICATION_FEATURE_NAME should cover multiple smaller features
-
this allows us to create a shorter documentation that is much friendlier to the end user. For example, instead of creating multiple sections for Sending messages, Editing messages, Deleting messages, … we can define a single Messages section that gives the user enough knowledge to work with messages. Then to give them more insight into mentioning users and text formatting we define new sections Formatting text and Tagging users that focus only on that. For example:
= {PRODUCT_NAME} {APP_NAME_MESSAGING}
{PRODUCT_NAME} {APP_NAME_MESSAGING} is a cloud messaging application designed for communication between team members.
It can be used by any user that has the correct permissions.
[IMPORTANT]
====
If you can't access the application, contact your system administrator.
====
To access the application, ...
== Messages
// ...
=== Sending messages
// ...
// Replying to messages
// ...
=== ...We should also cover:
- Getting Started
-
Cover the first steps that the user should take to get up and running. For example how to register, how to login, how to change their username/email, …
Administrator Guide
Provide a relatively high-level overview from the system administrators perspective. Provide an overview of the configuration, administration and management of the system; such as defining permissions, editing module fields, creating new users, creating and assigning roles, and so on. We should also cover the process of setting up a fresh instance and all the initial steps. We shouldn’t focus on how to create an integration; that is what the integrators guide is for. The section should describe multiple sub sections where each describes an application that Corteza defines; such as Corteza Messaging. For consistency we define the following structure:
= {APPLICATION_NAME}
// Provide a quick TL;DR of the application.
== {APPLICATION_FEATURE_NAME}
// Describe the feature to the extend where an administrator will be confident with using it.
// Keep it as short as possible but do provide all the important details!Important things we need to address:
- APPLICATION_FEATURE_NAME should cover multiple smaller features
-
this allows us to create a shorter documentation that is much friendlier to the administrator. For example, instead of creating multiple sections for Creating users, Deleting users, Editing users, … we can define a single Users section that gives the user enough knowledge to perform any user related operation. Then to give them more insight into managing roles, we define a new section Membership that focuses on role membership.
Also cover:
- Security
-
Describe in detail how the security system works - users, roles, access control, permissions and permission states (allow, deny and inherit). Aggregate all the available permissions for each system.
Integrator Guide
Provide a detailed overview of the entire integration process. It should provide enough insight into the system, terminology and other bits such as extension development so that the reader is able to extend the base Corteza for either themselves or a client. The document should be written for field experts, so we shouldn’t worry about their limited knowledge on the subject. The section should describe multiple sub sections where each describes an application that Corteza defines; such as Corteza Messaging. Each sub section should specify how to setup/configure a specific area of the application; for example "Setting up a namespace". Make sure to keep the sub sections relatively small! For consistency we define the following structure:
= {APPLICATION_NAME}
// Provide a quick TL;DR of the application.
== {APPLICATION_SECTION_NAME}
// Describe the section in enough detail, that the integrator will be able to confidently perform the given task related to the section.For example:
= {PRODUCT_NAME} {APP_NAME_COMPOSE}
// ...
== Setting up a namespace
A namespace encapsulates data related to a specific area (in database terminology it is a schema).
For example, if we are working on a CRM system (defining additional modules, changing fields) we would work under the CRM namespace.
=== Creating a namespace
// Things related to how to create/update/delete the namespace
// ...
=== Administration
// Things related to the administration, such as permissions
// ...Also cover:
- Security
-
Describe in detail how the security system works - users, roles, access control, permissions and permission states (allow, deny and inherit). Aggregate all the available permissions for each system.
- Extension Development
-
Describe in detail how the automation system works from the integrators perspective — how to create a new automation script, Corredor helper classes, API clients, … Go into details, but omit the implementation related specifics.
- Tips and Tricks
-
Hack down some findings, good practices, … discovered from past projects, such as creating a portal for end-users.
Developer Guide
Provide a low-level overview over the entire system and all the available features. It should focus on how a feature functions, what parts (endpoints, services, …) of the system are included to provide a general idea of the internal logic. It should not focus on implementation details (what functions are called and their arguments, what libraries are used) as it is visible from the source code. The section should describe multiple sub sections where each describes an application that Corteza defines; such as Corteza Messaging. For consistency we define the following structure:
= {APPLICATION_NAME}
// Provide a quick TL;DR of the application.
== {APPLICATION_FEATURE_NAME}
// Describe the feature to the extend where a maintainer understands what parts of the system are involved when working on this feature (improvements, bugfixes, ...).Important things we need to address:
- APPLICATION_FEATURE_NAME should cover multiple smaller features
-
this allows us to create a shorter documentation that is much friendlier to the reader. For example, instead of creating multiple sections for Creating users, Deleting users, Editing users, … we can define a single Users section that gives the reader enough knowledge to understand what parts are involved.
Additional sections to cover:
- Documentation
-
Well… this is it. If you’re reading this, then hi! Describe the different documentations, provide some guidelines and describe the process of contributing documentation.
Extensions
The purpose is to provide an overview of all available official extensions from the integrators perspective. Each extension should define it’s own section where it is described in detail. For consistency we define the following structure:
= {EXTENSION_NAME}
// Provide a quick TL;DR of the extension.
// Split this sub section further as you see fit.|
If you are developing your own extensions, provide your own documentation and don’t attempt to merge it here unless we agree on making it an official extension. |
Corteza Database
Overview
Current Corteza version only supports MySQL databases. This will change in the 2020.12.0 with the rework of the storage layer.
Corteza uses the Percona Docker container for the database.
Database structure
System
| Column | Type | Default | Description |
|---|---|---|---|
ts |
DATETIME NOT NULL |
NOW() |
|
actor_ip_addr |
VARCHAR(15) NOT NULL |
||
actor_id |
BIGINT UNSIGNED |
||
request_origin |
VARCHAR(32) NOT NULL |
||
request_id |
VARCHAR(64) NOT NULL |
||
resource |
VARCHAR(128) NOT NULL |
||
action |
VARCHAR(64) NOT NULL |
||
error |
VARCHAR(64) NOT NULL |
||
severity |
SMALLINT NOT NULL |
||
description |
TEXT |
||
meta |
JSON |
NULL |
| Column | Type | Default | Description |
|---|---|---|---|
id |
bigint(20) unsigned NOT NULL |
||
rel_owner |
bigint(20) unsigned NOT NULL |
||
name |
text NOT NULL |
something we can differentiate application by |
|
enabled |
tinyint(1) NOT NULL |
||
unify |
json |
NULL |
unify specific settings |
created_at |
datetime NOT NULL |
CURRENT_TIMESTAMP |
|
updated_at |
datetime |
NULL |
|
deleted_at |
datetime |
NULL |
| Column | Type | Default | Description |
|---|---|---|---|
id |
bigint(20) unsigned NOT NULL |
||
rel_owner |
bigint(20) unsigned NOT NULL |
||
label |
text NOT NULL |
something we can differentiate credentials by |
|
kind |
varchar(128) NOT NULL |
hash, facebook, gplus, github, linkedin … |
|
credentials |
text NOT NULL |
crypted/hashed passwords, secrets, social profile ID |
|
meta |
json NOT NULL |
||
expires_at |
datetime |
NULL |
|
created_at |
datetime NOT NULL |
CURRENT_TIMESTAMP |
|
updated_at |
datetime |
NULL |
|
deleted_at |
datetime |
NULL |
|
last_used_at |
datetime |
NULL |
| Column | Type | Default | Description |
|---|---|---|---|
id |
bigint(20) unsigned NOT NULL |
||
fqn |
text NOT NULL |
||
name |
text NOT NULL |
||
created_at |
datetime NOT NULL |
CURRENT_TIMESTAMP |
|
updated_at |
datetime |
NULL |
|
archived_at |
datetime |
NULL |
|
deleted_at |
datetime |
NULL |
| Column | Type | Default | Description |
|---|---|---|---|
rel_role |
bigint(20) unsigned NOT NULL |
||
resource |
varchar(128) NOT NULL |
||
operation |
varchar(128) NOT NULL |
||
access |
tinyint(1) NOT NULL |
| Column | Type | Default | Description |
|---|---|---|---|
id |
bigint(20) unsigned NOT NULL |
||
resource |
varchar(128) NOT NULL |
Resource that this reminder is bound to |
|
payload |
json NOT NULL |
Payload for this reminder |
|
snooze_count |
int(11) NOT NULL |
'0' |
Number of times this reminder was snoozed |
assigned_to |
bigint(20) unsigned NOT NULL |
'0' |
Assignee for this reminder |
assigned_by |
bigint(20) unsigned NOT NULL |
'0' |
User that assigned this reminder |
assigned_at |
datetime NOT NULL |
When the reminder was assigned |
|
dismissed_by |
bigint(20) unsigned NOT NULL |
'0' |
User that dismissed this reminder |
dismissed_at |
datetime |
NULL |
Time the reminder was dismissed |
remind_at |
datetime |
NULL |
Time the user should be reminded |
created_by |
bigint(20) unsigned NOT NULL |
'0' |
|
created_at |
datetime NOT NULL |
CURRENT_TIMESTAMP |
|
updated_by |
bigint(20) unsigned NOT NULL |
'0' |
|
updated_at |
datetime |
NULL |
|
deleted_by |
bigint(20) unsigned NOT NULL |
'0' |
|
deleted_at |
datetime |
NULL |
| Column | Type | Default | Description |
|---|---|---|---|
id |
bigint(20) unsigned NOT NULL |
||
name |
text NOT NULL |
||
handle |
text NOT NULL |
||
created_at |
datetime NOT NULL |
CURRENT_TIMESTAMP |
|
updated_at |
datetime |
NULL |
|
archived_at |
datetime |
NULL |
|
deleted_at |
datetime |
NULL |
| Column | Type | Default | Description |
|---|---|---|---|
rel_role |
bigint(20) unsigned NOT NULL |
||
rel_user |
bigint(20) unsigned NOT NULL |
| Column | Type | Default | Description |
|---|---|---|---|
rel_owner |
bigint(20) unsigned NOT NULL |
'0' |
Value owner |
0 for global settings |
name |
varchar(200) NOT NULL |
Unique set of setting keys |
value |
json |
NULL |
Setting value |
updated_at |
datetime NOT NULL |
CURRENT_TIMESTAMP |
When was the value updated |
updated_by |
bigint(20) unsigned NOT NULL |
'0' |
Who created/updated the value |
| Column | Type | Default | Description |
|---|---|---|---|
id |
bigint(20) unsigned NOT NULL |
||
text NOT NULL |
|||
username |
text NOT NULL |
||
name |
text NOT NULL |
||
handle |
text NOT NULL |
||
kind |
varchar(8) NOT NULL |
'' |
|
meta |
json NOT NULL |
||
rel_organisation |
bigint(20) unsigned NOT NULL |
||
rel_user_id |
bigint(20) unsigned NOT NULL |
||
created_at |
datetime NOT NULL |
CURRENT_TIMESTAMP |
|
updated_at |
datetime |
NULL |
|
suspended_at |
datetime |
NULL |
|
deleted_at |
datetime |
NULL |
|
email_confirmed |
tinyint(1) NOT NULL |
'0' |
Low Code
| Column | Type | Default | Description |
|---|---|---|---|
id |
bigint(20) unsigned NOT NULL |
||
rel_namespace |
bigint(20) unsigned NOT NULL |
||
rel_owner |
bigint(20) unsigned NOT NULL |
||
kind |
varchar(32) NOT NULL |
||
url |
varchar(512) |
NULL |
|
preview_url |
varchar(512) |
NULL |
|
size |
int(10) unsigned |
NULL |
|
mimetype |
varchar(255) |
NULL |
|
name |
text |
||
meta |
json |
NULL |
|
created_at |
datetime NOT NULL |
CURRENT_TIMESTAMP |
|
updated_at |
datetime |
NULL |
|
deleted_at |
datetime |
NULL |
| Column | Type | Default | Description |
|---|---|---|---|
id |
bigint(20) unsigned NOT NULL |
||
handle |
varchar(200) NOT NULL |
||
rel_namespace |
bigint(20) unsigned NOT NULL |
||
name |
varchar(64) NOT NULL |
The name of the chart |
config |
json NOT NULL |
Chart & reporting configuration |
created_at |
datetime NOT NULL |
CURRENT_TIMESTAMP |
updated_at |
datetime |
|
NULL |
deleted_at |
datetime |
| Column | Type | Default | Description |
|---|---|---|---|
id |
bigint(20) unsigned NOT NULL |
||
handle |
varchar(200) NOT NULL |
||
rel_namespace |
bigint(20) unsigned NOT NULL |
||
name |
varchar(64) NOT NULL |
The name of the module |
json |
json NOT NULL |
List of field definitions for the module |
created_at |
datetime NOT NULL |
CURRENT_TIMESTAMP |
updated_at |
datetime |
|
NULL |
deleted_at |
datetime |
| Column | Type | Default | Description |
|---|---|---|---|
id |
bigint(20) unsigned NOT NULL |
||
rel_module |
bigint(20) unsigned NOT NULL |
||
place |
tinyint(3) unsigned NOT NULL |
||
kind |
varchar(64) NOT NULL |
The type of the form input field |
|
options |
json NOT NULL |
Options in JSON format. |
|
default_value |
json |
NULL |
Default value as a record value set. |
name |
varchar(64) NOT NULL |
The name of the field in the form |
|
label |
varchar(255) NOT NULL |
The label of the form input |
|
is_private |
tinyint(1) NOT NULL |
Contains personal/sensitive data? |
|
is_required |
tinyint(1) NOT NULL |
||
is_visible |
tinyint(1) NOT NULL |
||
is_multi |
tinyint(1) NOT NULL |
||
created_at |
datetime NOT NULL |
CURRENT_TIMESTAMP |
|
updated_at |
datetime |
NULL |
|
deleted_at |
datetime |
NULL |
| Column | Type | Default | Description |
|---|---|---|---|
id |
bigint(20) unsigned NOT NULL |
||
name |
varchar(64) NOT NULL |
Name |
slug |
varchar(64) NOT NULL |
URL slug |
enabled |
tinyint(1) NOT NULL |
Is namespace enabled? |
meta |
json NOT NULL |
Meta data |
created_at |
datetime NOT NULL |
CURRENT_TIMESTAMP |
|
updated_at |
datetime |
NULL |
|
deleted_at |
datetime |
NULL |
| Column | Type | Default | Description |
|---|---|---|---|
id |
bigint(20) unsigned NOT NULL |
Page ID |
|
handle |
varchar(200) NOT NULL |
||
rel_namespace |
bigint(20) unsigned NOT NULL |
||
self_id |
bigint(20) unsigned NOT NULL |
Parent Page ID |
|
rel_module |
bigint(20) unsigned NOT NULL |
'0' |
|
title |
varchar(255) NOT NULL |
Title (required) |
|
description |
text NOT NULL |
Description |
|
blocks |
json NOT NULL |
array of blocks for the page |
|
visible |
tinyint(4) NOT NULL |
Is page visible in navigation? |
|
weight |
int(11) NOT NULL |
Order for navigation |
|
created_at |
datetime NOT NULL |
CURRENT_TIMESTAMP |
|
updated_at |
datetime |
NULL |
|
deleted_at |
datetime |
NULL |
| Column | Type | Default | Description |
|---|---|---|---|
rel_role |
bigint(20) unsigned NOT NULL |
||
resource |
varchar(128) NOT NULL |
||
operation |
varchar(128) NOT NULL |
||
access |
tinyint(1) NOT NULL |
| Column | Type | Default | Description |
|---|---|---|---|
id |
bigint(20) unsigned NOT NULL |
||
rel_namespace |
bigint(20) unsigned NOT NULL |
||
module_id |
bigint(20) unsigned NOT NULL |
||
owned_by |
bigint(20) unsigned NOT NULL |
'0' |
|
created_at |
datetime NOT NULL |
CURRENT_TIMESTAMP |
|
updated_at |
datetime |
NULL |
|
deleted_at |
datetime |
NULL |
|
created_by |
bigint(20) unsigned NOT NULL |
'0' |
|
updated_by |
bigint(20) unsigned NOT NULL |
'0' |
|
deleted_by |
bigint(20) unsigned NOT NULL |
'0' |
| Column | Type | Default | Description |
|---|---|---|---|
record_id |
bigint(20) NOT NULL |
||
name |
varchar(64) NOT NULL |
||
value |
longtext |
||
ref |
bigint(20) unsigned NOT NULL |
'0' |
Field is used for quicker lookups when it comes to values that represent a reference, such as recordID, userID and attachmentID. |
deleted_at |
datetime |
NULL |
|
place |
int(10) unsigned NOT NULL |
'0' |
| Column | Type | Default | Description |
|---|---|---|---|
rel_owner |
bigint(20) unsigned NOT NULL |
'0' |
Value owner |
0 for global settings |
name |
varchar(200) NOT NULL |
Unique set of setting keys |
value |
json |
NULL |
Setting value |
updated_at |
datetime NOT NULL |
CURRENT_TIMESTAMP |
When was the value updated |
updated_by |
bigint(20) unsigned NOT NULL |
'0' |
Who created/updated the value |
Messaging
| Column | Type | Default | Description |
|---|---|---|---|
id |
bigint(20) unsigned NOT NULL |
||
rel_user |
bigint(20) unsigned NOT NULL |
||
url |
varchar(512) |
NULL |
|
preview_url |
varchar(512) |
NULL |
|
size |
int(10) unsigned |
NULL |
|
mimetype |
varchar(255) |
NULL |
|
name |
text |
||
meta |
json |
NULL |
|
created_at |
datetime NOT NULL |
CURRENT_TIMESTAMP |
|
updated_at |
datetime |
NULL |
|
deleted_at |
datetime |
NULL |
| Column | Type | Default | Description |
|---|---|---|---|
id |
bigint(20) unsigned NOT NULL |
||
name |
text NOT NULL |
||
topic |
text NOT NULL |
||
meta |
json NOT NULL |
||
type |
enum('private', 'public', 'group') |
NULL |
|
membership_policy |
enum('featured','forced','') NOT NULL |
'' |
|
rel_organisation |
bigint(20) unsigned NOT NULL |
||
rel_creator |
bigint(20) unsigned NOT NULL |
||
created_at |
datetime NOT NULL |
CURRENT_TIMESTAMP |
|
updated_at |
datetime |
NULL |
|
archived_at |
datetime |
NULL |
|
deleted_at |
datetime |
NULL |
|
rel_last_message |
bigint(20) unsigned NOT NULL |
'0' |
| Column | Type | Default | Description |
|---|---|---|---|
rel_channel |
bigint(20) unsigned NOT NULL |
||
rel_user |
bigint(20) unsigned NOT NULL |
||
type |
enum('owner','member','invitee') |
NULL |
|
flag |
enum('pinned','hidden','ignored','') NOT NULL |
'' |
|
created_at |
datetime NOT NULL |
CURRENT_TIMESTAMP |
|
updated_at |
datetime |
NULL |
| Column | Type | Default | Description |
|---|---|---|---|
id |
bigint(20) unsigned NOT NULL |
||
rel_channel |
bigint(20) unsigned NOT NULL |
||
rel_message |
bigint(20) unsigned NOT NULL |
||
rel_user |
bigint(20) unsigned NOT NULL |
||
rel_mentioned_by |
bigint(20) unsigned NOT NULL |
||
created_at |
datetime NOT NULL |
CURRENT_TIMESTAMP |
| Column | Type | Default | Description |
|---|---|---|---|
id |
bigint(20) unsigned NOT NULL |
||
type |
mediumtext CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci |
message |
|
mediumtext CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL |
meta |
||
json |
NULL |
rel_user |
|
bigint(20) unsigned NOT NULL |
rel_channel |
||
bigint(20) unsigned NOT NULL |
reply_to |
||
bigint(20) unsigned NOT NULL |
'0' |
created_at |
|
datetime NOT NULL |
CURRENT_TIMESTAMP |
updated_at |
|
datetime |
NULL |
deleted_at |
|
datetime |
NULL |
replies |
| Column | Type | Default | Description |
|---|---|---|---|
rel_message |
bigint(20) unsigned NOT NULL |
||
rel_attachment |
bigint(20) unsigned NOT NULL |
| Column | Type | Default | Description |
|---|---|---|---|
id |
bigint(20) unsigned NOT NULL |
||
rel_channel |
bigint(20) unsigned NOT NULL |
||
rel_message |
bigint(20) unsigned NOT NULL |
||
rel_user |
bigint(20) unsigned NOT NULL |
||
flag |
text |
created_at |
| Column | Type | Default | Description |
|---|---|---|---|
rel_role |
bigint(20) unsigned NOT NULL |
||
resource |
varchar(128) NOT NULL |
||
operation |
varchar(128) NOT NULL |
||
access |
tinyint(1) NOT NULL |
| Column | Type | Default | Description |
|---|---|---|---|
rel_owner |
bigint(20) unsigned NOT NULL |
'0' |
Value owner |
0 for global settings |
name |
varchar(200) NOT NULL |
Unique set of setting keys |
value |
json |
NULL |
Setting value |
updated_at |
datetime NOT NULL |
CURRENT_TIMESTAMP |
When was the value updated |
updated_by |
bigint(20) unsigned NOT NULL |
'0' |
Who created/updated the value |
| Column | Type | Default | Description |
|---|---|---|---|
rel_channel |
bigint(20) unsigned NOT NULL |
'0' |
|
rel_reply_to |
bigint(20) unsigned NOT NULL |
||
rel_user |
bigint(20) unsigned NOT NULL |
'0' |
|
count |
int(10) unsigned NOT NULL |
'0' |
|
rel_last_message |
bigint(20) unsigned NOT NULL |
'0' |
Corteza Low Code
Record Value Validation
Record value validation allows us to assure data integrity and avoid problems consisting of empty fields and malformed email addresses.
|
Value validation can also perform operations that require API access, such as checking if we can send an email to the given address. |
Value validation can be performed on 3 places:
-
Inside client-script on
beforeFormSubmitevent, -
inside server-script on
beforeevents, -
automatically by the corteza-server value validator.
All validator errors returned by automation scripts are instances of validator.ValidatorError class, with the interface of:
interface ValidatorError {
kind: string;(1)
message: string;(2)
meta: { [key: string]: unknown };(3)
}| 1 | The kind of the error; for now, this can be an arbitrary string that describes the error. |
| 2 | The optional message with a more verbose error description.
Defaults to err.kind. |
| 3 | A loosely defined object that stores any additional metadata, such as field name, recordID, … |
The validation flow
-
Dispatch
beforeFormSubmitevent,-
if any automation script returns a
validator.ValidatorError, stop the execution and show the errors,
-
-
run the
validator.RecordValidatorsystem,-
on
validator.ValidatorError, dispatch theonFormSubmitErrorevent that can be used to fix the validation errors, -
run the
validator.RecordValidatorsystem,-
if errors persist, stop the execution and show the errors,
-
-
-
request record create/update on the API,
-
if the API returns a
validator.ValidatorError, stop the execution and show the errors.
-
Extensions
|
This section covers the system behind extensions. If you’re interested in extension development, refer to the integrator guide. |
Overview
Components
- Corteza Corredor Server
-
A Node.js service written in TypeScript. It is the heart of the system as it parses and serves automation scripts. It also executes server-scripts.
- Corteza Server
-
The Corteza server is responsible for automation script execution. On its own, Corredor server is unable to do any code execution; it must be invoked either via Corteza server or manually via gRCP protocol.
- Corredor Client
-
Each Corteza webapp that allows client-script execution implements this. The Corredor Client is responsible for client-script registration and their execution. Automation scripts are received from the Corteza Server.
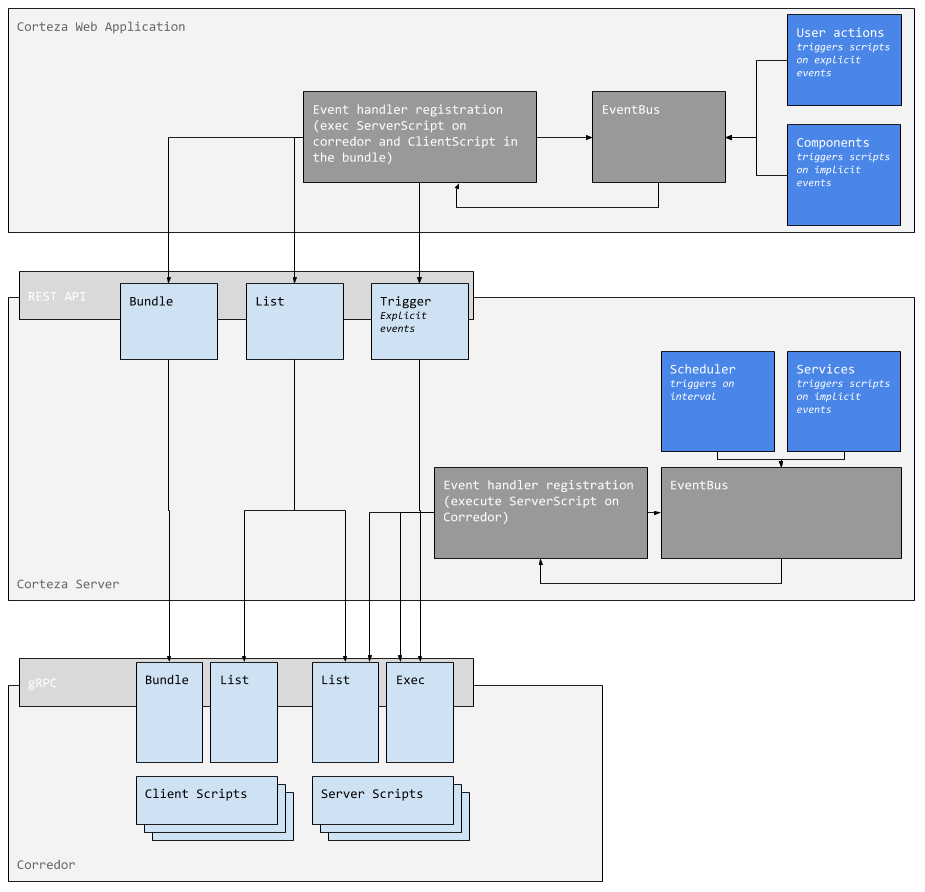
Corredor Server
Corredor server is mainly responsible for:
-
Loading, processing and serving automation scripts,
-
server-script execution.
Server-scripts file structure
/server-scripts (1)
/... (2)| 1 | Root folder for all server scripts (under each search path). |
| 2 | Undefined file structure; can be defined as needed. |
Client-scripts file structure
/client-scripts (1)
/auth (2)
/... (7)
/admin (3)
/... (7)
/compose (4)
/... (7)
/messaging (5)
/... (7)
/shared (6)
/... (7)| 1 | Root folder for all client scripts (under each search path). |
| 2 | Defines a bundle for Corteza Auth. |
| 3 | Defines a bundle for Corteza Admin. |
| 4 | Defines a bundle for Corteza Low Code. |
| 5 | Defines a bundle for Corteza Messaging. |
| 6 | Reserved directory for any shared logic, such as custom libraries, assets, … |
| 7 | Undefined file structure; can be defined as needed. |
Automation script processing
Flow outline:
- Scan extensions defined in the .env
-
Go over all extensions defined in
the CORREDOR_EXT_SEARCH_PATHS.env variable. Extensions are separated by:.
|
Note that all of the following steps are performed for each of the extensions. |
- Dependency management
-
Load all requested dependencies by the given extension.
|
Dependencies are scoped to the extension that has requested them. If two extensions wish to use the same dependency (axios for example) they both should define it. |
- Parse server-scripts
-
Go over each script file defined inside the
server-scriptssub-tree. Parse the script and extract all the important bits such as dependencies, triggers, iterators and the exec function itself.
|
At the moment server scripts are not bundled. |
- Parse client-scripts
-
Go over each script file defined inside the
client-scriptssub-tree. Parse the script and extract all the important bits such as dependencies, triggers, iterators and the exec function itself. Create a per-app bundle containing relevant automation scripts, dependencies and other relevant bits. Refer to Client-script bundling for details about creating bundles.
|
Bundling is done using webpack. |
- Prepare a list of available scripts
-
This allows us to inspect what scripts were loaded from inside web-apps. It also simplifies the process of determining available automation scripts from inside client-script bundles.
|
Failing automation scripts are also included in this list but provide a descriptive error. This allows easier debugging. |
Automation script naming
Corredor determines automation scripts name on-the-fly from the extension and it’s relative path. This simplifies the script’s definition as we don’t need to worry about unique names and possible conflicts between extensions. Script name is defined as:
/${path to script}/${file name}:${export name}(1)(2)(3)| 1 | Path to the script file, excluding the search path. |
| 2 | The script’s file name. |
| 3 | Used export name; this will normally be default. |
|
The base search path of the extension is excluded from the script’s name. This allows easier reusability across different systems that don’t define the same file hierarchy. |
Client-script bundling
Client-scripts are bundled using webpack. Bundles help us assure consistent code execution between different user-agents and allow the use of external node dependencies.
The bundling process creates multiple bundles, one for each available application (Auth, Admin, Low Code, …). This simplifies the process of registering client-scripts on the client-side.
|
Bundle name is determined from the extensions file-structure:
|
The bundling process creates a boot loader file for each available application.
The file consists of { name, triggers, security } JSON objects for each available automation script.
The Webpack is then executed over each boot loader file to create a bundle for the given application.
If the application doesn’t define any automation scripts the bundling process is omitted.
gRPC server
Corredor server allows communication via the gRPC server via the gRPC protocol via the following services:
-
Server scripts with list and exec procedures,
-
client scripts with list and bundle procedures.
Refer to protobuf service definition for the details on the definitions.
|
You can use BloomRPC or similar when working solely on the Corredor server to remove the need for the Corteza server. |
Server-script execution
|
Corredor server is and should not be able to perform any code execution on its own. Any execution is and should be invoked either by the Corteza server or manually via gRPC protocol. |
Watching for changes
When the Corredor server is running in development mode or is configured so via the .env variables it uses file watchers to detect changes to the extensions and dependency definition files. When a change occurs, the server wil restart the entire Automation script processing flow.
Corteza Server
Corteza server is mainly responsible for:
-
Providing endpoints for fetching scripts and script execution,
-
scheduling deferred automation scripts,
-
requesting script execution on the Corredor server.
|
The following automation scripts are executed directly by the Corteza server:
|
Script endpoints
- [APPLICATION NAME]/automation/list
-
Provides a list of available automation scripts for the given Corteza application.
- [APPLICATION NAME]/automation/{bundle}-{type}.{ext}
-
Provides the client-script automation bundle for the given Corteza application.
|
If the given application doesn’t have it’s own bundle, the endpoint returns a 404 not found. |
- [APPLICATION NAME]/automation/trigger
-
Requests explicit server-script execution on the Corredor server.
- system/sink
-
Provides an endpoint that server-scripts are able to listen on and perform operations for.
Event bus
Any executable automation script is registered on the event bus. Whenever any part of the system might require a script execution, it dispatches an event on the event bus and any registered script that conforms to the requirements is executed on the Corredor server.
The script registration flow is as follows:
- Fetch available scripts from the Corredor server
-
This provides a full automation script list, including invalid scripts (those that didn’t compile successfully) — these are excluded.
- Prepare a lightweight script representation
-
Define a lightweight
handlerstruct for easier execution determination and script identification. Execution is performed by the handler function that allows a bit more flexibility on how to handle each script type.
|
Note that the iterators handler function is a bit more complex than the rest. |
- Register the script on the event bus
-
Register the above simplified automation script on the event buss.
Now when it comes to script execution, this is invoked by dispatching an event on the event bus. To outline the flow:
- Dispatch the event on the event bus
-
An event is a generic interface that allows the event bus to determine what scripts should be executed.
- Execute the scripts
-
Iterate and execute any automation script that conforms to the dispatched event. This can be done either synchronously or asynchronously.
Server side script execution
|
If the result of an automation script is an |
- Explicit
-
Explicit scripts are invoked by the front-end applications or manually via the API. When invoked, an event is constructed and dispatched via the event bus.
|
This is also true for sink script execution. |
- Implicit
-
These are triggered as a side-effect of another operation, such as record creation, user registration, password change, … Each part of the system that performs some operation that may invoke script execution generates an event and dispatches it on the event bus.
|
The same is also true for the Scheduler. |
- Iterator
-
Iterator script execution is invoked like any other deferred script. The important difference is that a new instance is executed for every resource that matches the trigger’s constraints.
If 10 records match the provided filter, the script will be executed 10 times.
System sink
System sink allows the implementation of custom endpoints on the Corteza server. This can be used for things like webhooks.
-
intercept any HTTP request on the
/sinkendpoint, -
basic request validation (provided required parameters),
-
validate request against the sink’s signature,
-
process request based on:
-
Content-Typeor any other HTTP header, -
remote address (IP),
-
request method and path,
-
username and password (HTTP basic auth),
-
GET (query string) parameters,
-
POST parameters,
-
-
generate an event and dispatch it via the event bus.
Scheduler
The scheduler system is responsible for triggering deferred scripts. At it’s core, scheduler is a "simple" ticker that dispatches periodical event on the event bus.
|
The interval is "hard-coded" to 1minute but that can be made configurable in the future. |
|
There is no mechanism in place that would prevent the automation scripts to overlap. For example:
This could be improved in the future. |
Corredor Client
Corredor client is mainly responsible for:
-
Script registration on the event bus,
-
registering available UI hooks,
-
script execution; either locally or on the server.
Event bus
Any executable automation script is registered on the event bus. Whenever any part of the system might require a script execution, it dispatches an event on the event bus and any registered script that conforms to the requirements is executed on the Corredor server.
|
The event bus concept follows the same pattern as the Corteza server does. |
- Fetch available script bundle from the Corteza server
-
This provides available client-script automation scripts defined for the given application. This allows us to register available client-scripts.
- Fetch available scripts from the Corteza server
-
This provides a full automation script list, including invalid scripts (those that didn’t compile successfully) — these are excluded. This allows us to register explicit server-scripts.
- Prepare a lightweight script representation
-
Define a lightweight
Handlerobject for easier execution determination and script identification. Execution is performed by the handler function that allows a bit more flexibility on how to handle each script type. - Register the script on the event bus
-
Register the above simplified automation script on the event buss.
Now when it comes to script execution, this is invoked by dispatching an event on the event bus. To outline the flow:
- Dispatch the event on the event bus
-
An event is an object that allows the event bus to determine what automation scripts should be executed and their execution context/arguments.
- Execute the scripts
-
Iterate and execute any automation script that conforms to the dispatched event. This can be done either synchronously or asynchronously.
|
A big difference between server-side and client-side execution is that client-side arguments are provided as references and not as copied objects. Any change done to the original object is reflected to the original object. |
UI hooks
A UI hook defines a component that represents an explicit automation script — either a client-script or a server-script. UI hooks mainly define the component properties — what element to render, styling, what script should be executed, additional context, …
It is up to the web-app to render these components and dispatch events on the event bus when needed.
Script execution
|
Corredor client is able to interact with some UI elements such as |
- Explicit
-
Explicit scripts are invoked by the user by explicitly invoking the above mentioned UI hooks. The web-app creates an event and dispatches it on the event bus. The handler function requests the script’s execution on the Corteza server.
|
An event caused by an explicit script will provide the script name that should be executed. Implicit events do not. |
- Implicit
-
These are triggered as a side-effect of another operation, such as form submission, view render, validation error, … Each part of the system that performs some operation that may invoke script execution generates an event and dispatches it on the event bus.